
Tegnap volt a data science versenyünk élő döntője. Az egyik döntősünk egy olyan trükköt is bedobott, amit szerintem mindenkinek érdemes ellesnie…
Egyébként a dobogósaink:
- Nagy Roland 🏆
- Horváth Bernadett
- Berki Tamás
Gratulálunk és nagy köszönet mindhármuknak! Képeket az eseményről posztolok majd a Linkedin-emre.
Na de vissza a *titkos trükkhöz*. (Najó, annyira nem is titkos — főleg ez után a poszt után.)
Mitől fut gyorsan egy kutya?
Csak a kontextus miatt, villámgyorsan (és eléggé leegyszerűsítve) leírom a problémát, amit a versenyzőinknek meg kellett oldania:
- Adott egy nagy adathalmaz, ami kutya-váltó-futóversenyek adatait tartalmazza. (A sportág pontos neve: Flyball. A lényege, hogy 4 kutya fut egy csapatban, egy pályán, egymást váltva. Egy versenyen több ilyen csapat is indul. Amelyik négyes-csapat a leggyorsabban ér a célba, az nyer.)
- Adott egy kérdés: mi befolyásolja legjobban a kutyák futási teljesítményét?
Kezdetben egyszerűnek tűnik a feladat.
Vizsgáljuk pl. hogy a nagyobb vagy a kisebb kutyák futnak gyorsabban…
Aztán vizsgáljuk, hogy hány éves kutyák futnak a legjobban…
Vagy nézzük meg, hogy melyik kutyafaj a legügyesebb…
De aztán elkezd bonyolódni a kérdéskör:
- Hány órakor teljesít a legjobban a csapat?
- Vajon az, hogy ivaros vagy ivartalan kutya jön egymás után, befolyásolja a futásidőt?
- És a kan/szuka váltásnak van hatása?
- Az, hogy ismerik egymást a kutyák, számít a futásidőben?
- És akkor még dobjuk hozzá az időjárási körülményeket is a képlethez…
- …
- …
Minél több elemzést csinálunk, annál több új kérdés merül fel.
Erről a data science versenyünk indulói azt hiszem sokat tudnának mesélni.
De az az igazság, hogy ez szinte minden valós üzleti projektekben pont ugyanígy néz ki.
Ebben nyújthat nekünk segítséget egy apró Machine Learning-es módszer.
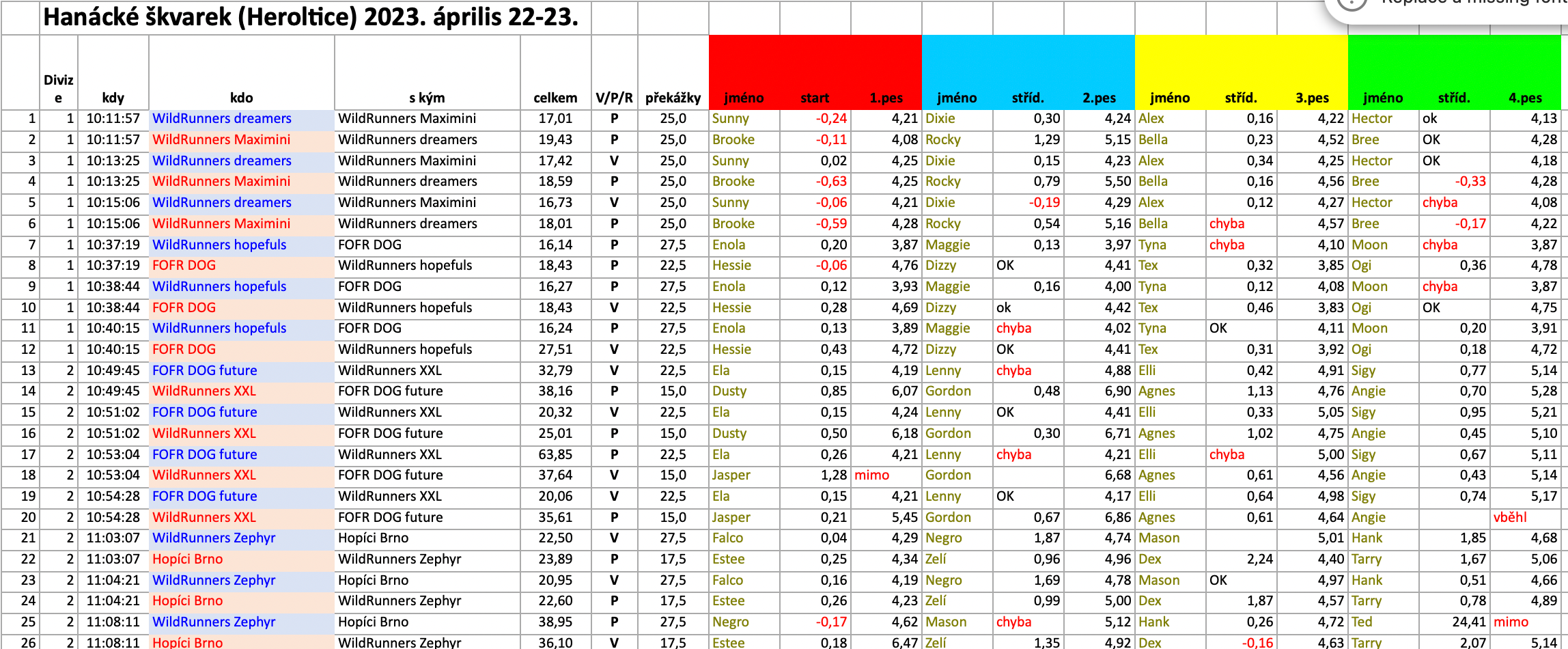
Amúgy itt egy screenshot/részlet a kellemesen kellemetlen kis dataset-ről, amit a versenyben kellett elemezni. 😈
Machine Learning röviden
Mielőtt leírom a konkrét módszert, gyorsan az ML-ről néhány szó.
A Machine Learning algoritmusokat például akkor vesszük elő, amikor:
- előrejelezni szeretnénk valamit (pl. gyárban: „várhatóan ez a gép el fog romlani egy hónapon belül”)
VAGY - osztályozni (pl. SaaS bizniszben: „ez a nem-fizetős user nagyon hasonlít a fizetős user-ekre”)
VAGY - neadjisten’ klasztereznénk egy picit (pl. egy boltban: „ezeket a termékeket jellemzően együtt vásárolja egy adott ügyfélkör”)
- …
(Ez most csak pár példa, de egy későbbi blogposztban majd jobban belemegyek ebbe is.)
A Machine Learning projektek működősének a lényege (legalább is a predikciós és a klasszifikációs eljárások zöménél) az, hogy:
- van egy csomó bemeneti változónk
- és van egy kimeneti változónk, amire optimalizálni szeretnénk
Íme egy egyszerű, hétköznapi példa:
SZITUÁCIÓ ÉS MEGOLDANDÓ PROBLÉMA:
Bemész a boltba, vásárolsz és szeretnéd eldönteni, hogy melyik sorba érdemes beállni fizetésnél.
KIMENETI VÁLTOZÓ (erre optimalizálsz):
Sorban állás ideje. (Ez legyen minél kisebb, hogy a leggyorsabban kijuss a boltból.)
BEMENETI VÁLTOZÓK (ezeket lehetnek hatással a kimeneti változódra):
- hányan állnak egy adott sorban
- mennyi termék van a sorban állók kosarában
- mennyi a sorban állók átlag életkora
- …
Ha ezt a problémát egy Machine Learning-es módszertannal oldanánk meg, akkor adnánk az algoritmusunknak mondjuk két évnyi adatot a múltból és az kiszámolná, hogy a bemeneti változók közül melyik mekkora arányban hat a kimeneti változónkra. Ez alapján az adott konkrét szitura vonatkoztatva pedig kiszámolná, hogy melyik sorban mennyi lehet a sorban állási idő — ez alapján pedig kiválaszthatjuk a legjobb sort.
Megjegyzés: persze ismét csak egyszerűsítek — az ML-ben egy csomó nüansz és megoldandó probléma van, de hasonlatnak szerintem ez a példa jó lesz.
A bemeneti változók fontossága
Na és akkor itt a kulcs, amit elemzési projektekbe is át tudunk hozni egy ML (gépi tanulásos) projektből.
Gyakran nem az a legnagyobb üzleti érték számunkra, hogy tudjuk, hogy melyik konkrét sorba kell beállnunk, hanem az, hogy tudjuk, hogy melyik bemeneti változó hogyan hat a kimeneti változónkra.
(Ugyebár sokszor nem a „mit?”, hanem a „miért?” az érdekes.)
…
Visszatérve a kutyás példára, Roland, a DS versenyünk győztese azt mesélte nekem a szünetben, hogy bár ő javarészt egyszerű visszatekintő elemzésekkel operált, azért használt egy kis Machine Learning-et, hogy leellenőrizze, hogy az algó is ugyanazokat a változókat tartja-e fontosnak egy kutya futás idejében, mint amiket ő talált. Ezt kapta:
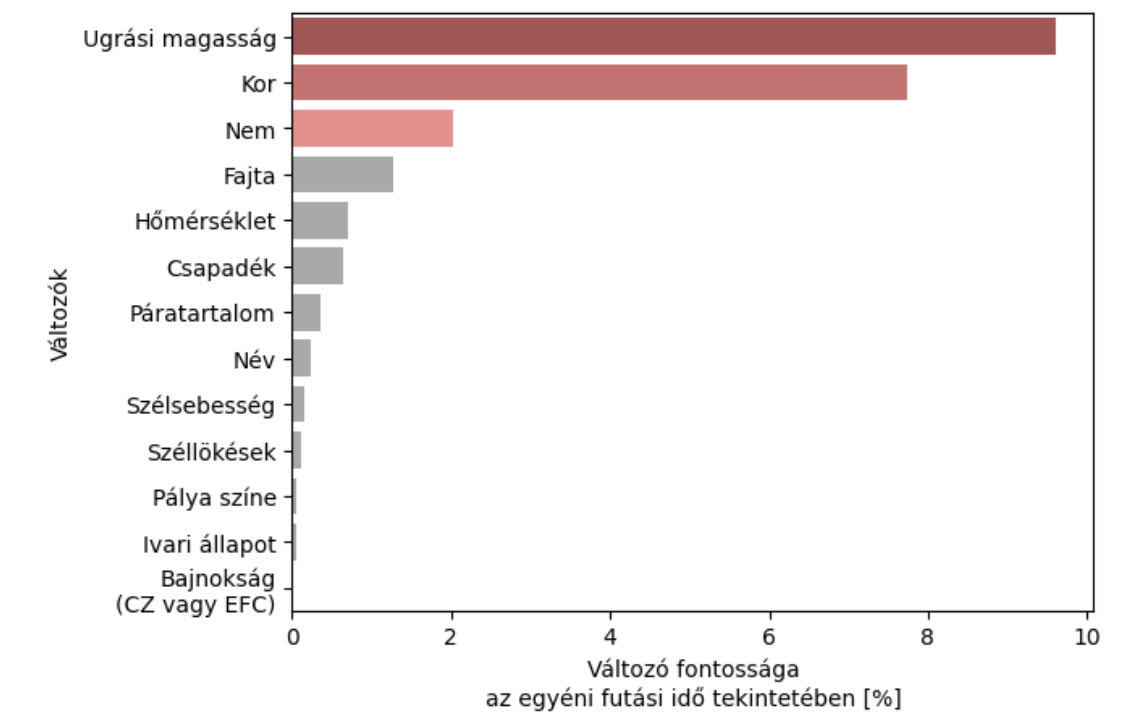
Ez persze csak egy apró lépés volt az amúgy nagyon komplex elemzéséből, de azért én erre felkaptam a fejem (és tudom, hogy a zsűrinek is tetszett).
Meg azért milyen király egy akármilyen valós életbeli adatos projektben, amikor kapunk egy ilyen chart-ot, ami segít elindulni, hogy egyáltalán milyen irányba nézelődjünk az amúgy végtelen adathalmazunkban.
Egy üzleti példa
Mutatok egy másik példát.
A Data36.com nemzetközi blogján egy időben folyamatosan írtam az angol nyelvű cikkeket. Persze kíváncsi voltam, hogy melyik cikkek vannak legnagyobb hatással a későbbi konverzióra (az én esetemben a kurzusvásárlásokra).
Az adat megvolt, úgyhogy gyorsan én is megcsináltam az elemzésemet:
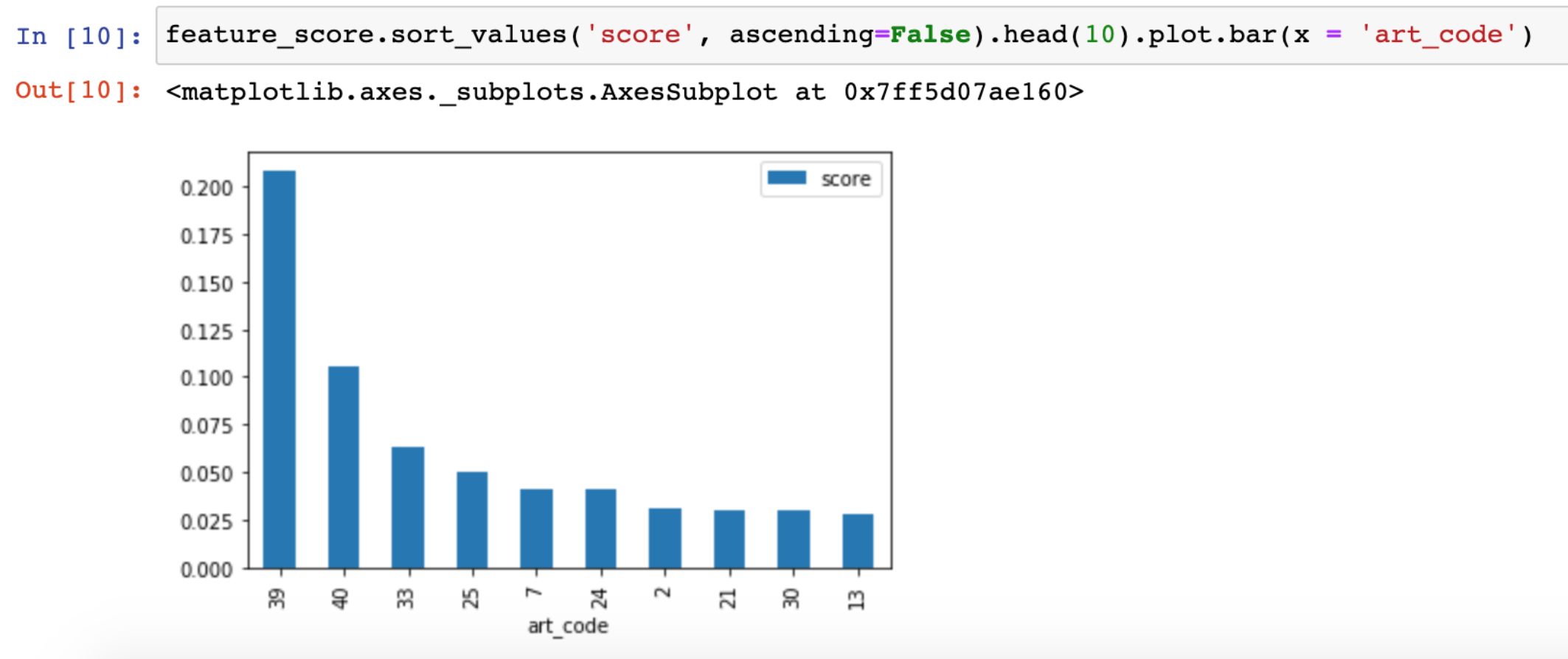
A módszer elég hasonló Rolandéhoz — csak nálam minden egyes oszlop egy specifikus cikk elolvasását jelenti itt. Kódolva van az ábrán, de a 39-es jelű pl. a „Learning Data Science (4 Untold Truths)” című cikkem. Tehát ennek a cikknek az elolvasása van a legnagyobb hatással arra, hogy egy olvasó később vásárló legyen nálam. (Egyébként a következő három cikk is nagyon hasonló, bevezető jellegű és témájú írás.)
Ez az apró és gyors insight tök sokat segített nekem abban, hogy milyen új cikkeket írjak — illetve abban is, hogy melyik cikkeket érdemes jobban a közönségem elé tenni a nemzetközi hírlevelemben, hirdetésekben, stb, stb.
Milyen módszerek vannak a változók fontosságának értékelésére?
Ezt a fajta elemzést a bemeneti változók fontosságáról és súlyáról sokféle módon meg lehet csinálni Python-ban.
Több módszer és implementáció is létezik. Mindegyik másban erős, kicsit különböznek egymástól (más eredményt is adhatnak) — sőt nem is mindegyiket lehet minden modellnél használni.
…
- Roland a versenyben SHAP módszertant/könyvtárat használta. (LINK)
- Én a cikkes megoldásomban egy feature_importances_ nevű függvényt futtattam (LINK)
- De láttam már senior adatos szakembert egy Partial Dependence Plots (PDP) nevű módszert is használni (LINK)
- …
Szóval jó sok megoldás van, különböző esetekre, különböző matekkal a háttérben.
A ChatGPT-vel csináltattam egy kedves kis táblát, ami segít elindulnod az úton: itt.
…
Összefoglalva
Szerintem ez a bemeneti változó elemzés egy baromi hasznos kis fogás. Én használom olyan projektekben is, ahol amúgy közvetlenül nem biztos, hogy elővenném a klasszikus értelemben vett gépi tanulást.
A végére azért hadd tegyem hozzá azt az általános data science intelmet, hogy:
Bár látni fogod, hogy egy-egy ilyen megoldást Python-ban könnyedén, pár sorban le tudsz futtatni (különösen, ha már az ML modelled megvan), de ahhoz, hogy ne menjen félre semmi az értelmezésben, minden esetben meg kell értened mélyen, hogy pontosan mit is mond egy-egy adott módszertan a változók fontosságáról. (Ehhez jó alapot nyújt a fenti kis ChatGPT-s táblácska, illetve érdemes mélyebben beleásni a módszerek dokumentációiba is.)
Mára ennyi!
Remélem, érdekes volt!
Köszi, és üdv
Mester Tomi