Adott egy adathalmaz, ami whisky neveket tartalmaz.
Itt egy részlet belőle:
- Highland Park 12 Year Old
- C & J McDonald’s 12 Year Old
- Yamazaki 18 Year Old
- Royal Salute 21 Year Old
- Glenfiddich Pure Malt 8 Year Old
- Bruichladdich 1989 14 Year Old
- Van Winkle 12 Year Old Lot ‘B’
- Dailuaine 1966 13 Year Old Sherry Wood
- Caol Ila 1990 29 Year Old
- Glenfiddich 26 Year Old Grande Couronne
- Macallan 12 Year Old
- Tamdhu 10 Year Old
- Yamazaki 12 Year Old
- Ben Nevis 1996 19 Year Old Cask 1424
- …
(Ez csak egy oszlop a jelenleg 1.084.336 soros táblából.)
A feladat egyszerű:
Mi az az adattisztítási módszer, amivel megtudhatjuk ezekből az adatokból kiindulva a whisky márkáját is?
Pl.:
- Yamazaki 18 Year Old –» Yamazaki
- Caol Ila 1990 29 Year Old –» Caol Ila
- Macallan 12 Year Old –» Macallan
- …
Elsőre könnyűnek tűnik, de aztán jönnek a különleges esetek.
Ebben a levélben először elmondom, hogy mi nem működött, aztán adok egy mentális modellt, ami megoldotta ezt a problémát és egy csomó más adattisztítási feladatnál is alkalmazható lesz.
Nem működött #1:
Az egyszerű megoldások rajongója vagyok.
Az első triviális lehetőség:
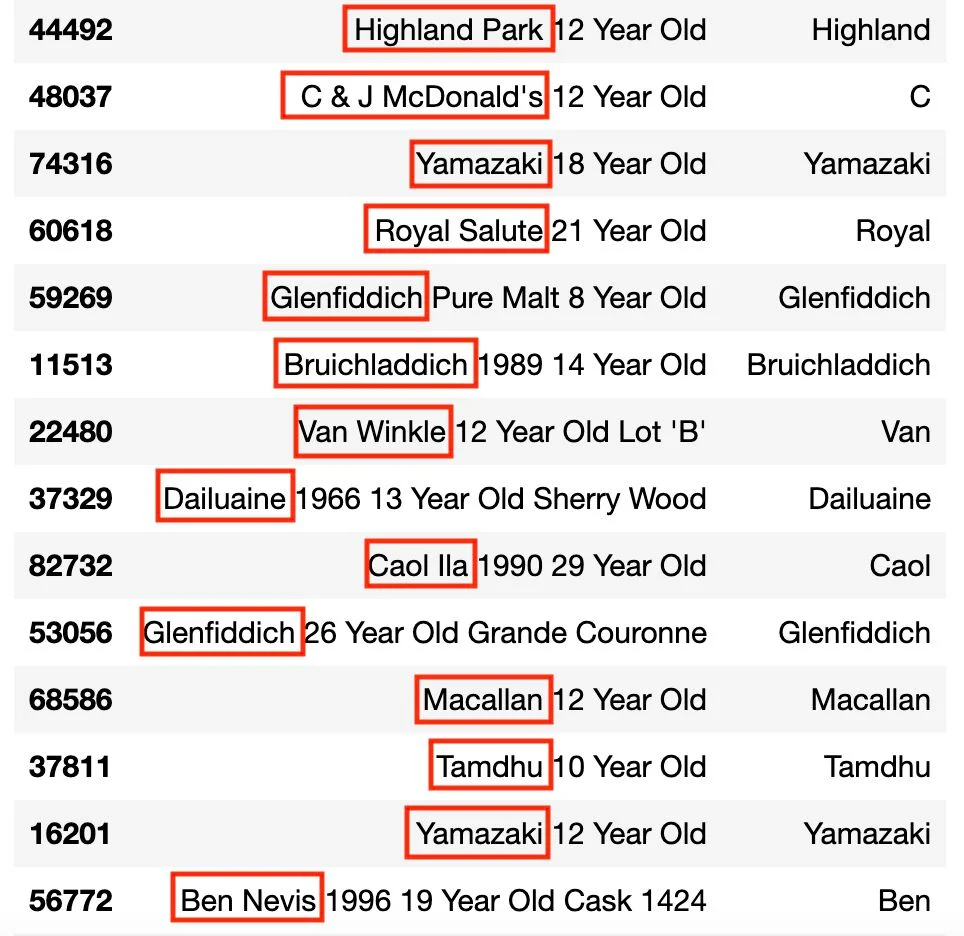
Legyen mindig a whisky nevének az első szava a márkanév.
Gyorsan kiderül, hogy miért nem működik: vannak két szavas márkanevek is. ¯\_(ツ)_/¯
Pirossal keretezve az elvárt megoldás – mellette levő oszlopban az első-szó-mint-márkanév megoldás:
Nem működött #2:
Aztán próbálkoztam azzal, hogy:
Minden „__ Year Old” mintázat előtti karakterlánc legyen a márkanév.
Sajnos ez sem működik. Például:
- ‘Glenfiddich Pure Malt 8 Year Old’:
- elvárt output: ‘Glenfiddich’
- output: ‘Glenfiddich Pure Malt’
- ‘Bruichladdich 1989 14 Year Old’
- elvárt output: ‘Bruichladdich’
- output: ‘Bruichladdich 1989’
…
…
Szóval egyre jobban bonyolódott a dolog.
Persze el lehet kezdeni a különleges eseteket egyesével kezelni, de valamiért az az érzése van az embernek, hogy egy márkanév kiszedésére kéne lennie valami egyszerű algoritmusnak.
Van is.
Mindjárt elárulom, de előtte nézzük, hogy mások miket írtak.
A Linkedin kommentelők megoldásai között van egy-két csemege!
Annó még kidobtam a Linkedinemre is a kérdést, kommentben nagyon jó ötleteket kaptam.
Ide kiemelek kettőt ezekből:
- ChatGPT, LLM, AI és társai:
Többen is írták, hogy egy large-language-model-es megoldással (pl. ChatGPT) jól megugorható a probléma. Nagyon nagy eséllyel igazuk van!Nekem itt a legfőbb kételyem a költségoldal. Az eredeti adathalmaz közel egymillió soros. A jelenlegi GPT API árazással szerintem ez kb. 30.000-40.000 forintos költség lenne. Belefér, de ennyi pénzért már megérheti egy gyorsabb algót kitalálni, ami ingyen van. 🙂
A másik probléma meg persze a megbízhatóság… - Bálint (GDPR-okokból csak keresztnévvel szerepeltetem itt ) ötlete is működőnek tűnik erre a konkrét problémára! (Köszi neki a kommentet!)
Az általánosan működő, egyszerű adattisztítási megoldás…
Itt jelezném, hogy ezen a problémán eredetileg még 2022-ben dolgoztam.
ChatGPT-előtti időszámítást írunk…
Egy olyan világot képzelj el, ahol még te magad írtad a Python-kódodat és senki nem mondott neked olyan, hogy „Elnézést, én csak egy nagy nyelvi modell vagyok…”
Szóval pár órája már agyaltam a megoldáson és feldobtam a kérdést Twitter-en is. Ez a válasz érkezett:

Zseniális!
Miért szorítkoznánk csak erre az eredeti dataset-re, amikor kb. egy perc alatt le tudjuk húzni az összes létező whisky brand-nevet az internetről?!
És valóban, ez a megoldás nagyszerűen működik!
- Letöltöttem az összes whisky márkanevet a Wikipedia megfelelő cikkéből.
- Össze-match-eltem a meglevő whisky nevekkel.
Ha benne van a márkanév a whisky nevében, akkor az a márka lesz a nyerő. (Volt egy-két edge-case, amit egy if-elif-else statement-tel kezelni kellett, de az már kb 5-10 perc munkával megoldható volt.) - És kész is vagyunk.
Megjegyzés: arról most nem beszélek, hogy az eredeti whisky nevekben volt pár elgépelés, ami még csavart egyet a dolgon. Erre is van gyors megoldás amúgy. De erről majd máskor.
Szóval több jó megoldás is van, de ezt az egyet azért akartam külön megmutatni, mert ez általánosan is alkalmazható egy csomó más adattisztítási feladatnál.
A tanulságok:
- Ne feledd, nem csak az a dataset létezik, amiből dolgozol. Sokat segíthet egy-egy publikus külső adathalmaz bevonása a projektedbe.
- (És ahogy Attila írta:) Ha egy adattisztítási problémából „data matching” problémát tudsz varázsolni, sokszor sokkal egyszerűbb dolgod lesz.
Remélem, a közeljövőben te is tudod majd alkalmazni ezt a trükköt! 😉
Most megyek vissza dolgozni! Viszlát! 👋
…
JA IGEN!
Ha idáig végigolvastad a levelet, akkor mostanra biztosan megkaptad a data karrier kimaxolva ajándék videót a másik emailben.
Köszi és üdv,
Mester Tomi
ui.: csekkold a Data Science Klubot is!